Python 语言进阶 —— 多线程
基本概念
在 Python 中,多线程是一种并发编程的技术,允许程序同时执行多个线程。多线程可以使程序在执行多个任务时更有效地利用 CPU
资源,并且可以提升程序的响应能力。线程是操作系统能够进行运算调度的最小单位
,它被包含在进程之中,是进程中的实际运作单位。多线程指的是在同一个程序中同时运行多个线程。在Python编程中,多线程是一种常用的并发编程方式,它可以有效地提高程序的执行效率,特别是在处理I/O密集型任务时。
一个线程完整的生命周期主要由五个状态构成:创建、就绪、运行、阻塞、死亡。
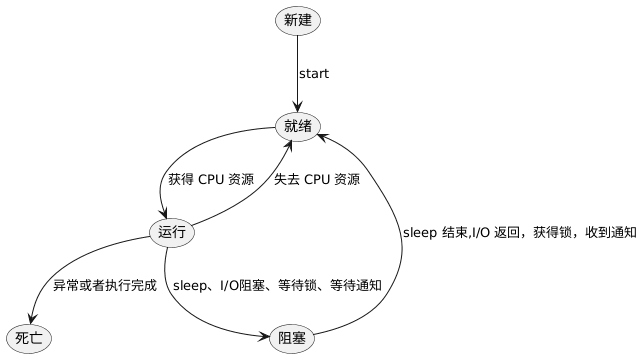
新建 一个线程后,调用其 start() 方法后,线程对象就处于就绪状态。线程什么时候运行取决于何时获得 CPU 的调度资源。只有当线程获取到
CPU 的调度资源后,线程的状态才会从 就绪 状态变成 运行 状态。当处于运行的线程,会由于自身原因(比如调用了 sleep
方法)或在外部因素(阻塞式的 I/O 方法)导致线程变成 阻塞 状态。只有当 阻塞 的因素被解除,线程才会由 阻塞
状态再次变成 就绪 状态。当线程执行完毕或者异常退出,表明线程已经进入到了 死亡 状态,随后线程对象被系统销毁被释放内存。
Q:为什么是并发和并行技术?
并发(Concurrency):指多个任务在重叠的时间段内启动、运行和完成,但不一定同时进行。并发可以让程序在处理多个任务时更具响应性。
并行(Parallelism):指多个任务同时执行。在多核 CPU 上,线程可以真正地同时执行,从而提高计算性能。
主线程和子线程
通常,我们所说的多线程实际上值得就是在主线程中运行多个子线程,而主线程默认是我们 Python
编译器执行的线程。所有子线程和主线程都同属于一个进程。在未添加子线程的情况下,默认就只有一个主线程在运行。
创建一个线程
Python 标准库提供了线程模块 threading,该模块 Thread
对线程的封装,提供了简单的实现接口。想要创建一个线程,需要创建 Thread 实例,然后调用它的 .start() 方法启动这个线程。
| Example 1 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | import threading
import time
def my_thread_function(name):
print(f'Thread {name}: running')
time.sleep(5)
print(f'Thread {name}: done')
if __name__ == '__main__':
print('Main: before creating thread')
x = threading.Thread(target=my_thread_function, args=('1',))
print('Main: before running thread')
x.start()
time.sleep(1)
print('Main: after running thread')
print('Main: all done')
|
上述程序使用函数 my_thread_function() 和 args=('1',) 创建了一个 Thread 实例。当执行上述程序,输出如下:
Main: before creating thread
Main: before running thread
Thread 1: running
Main: after running thread
Main: all done
Thread 1: done
Process finished with exit code 0
当主函数结束后,程序需要等待子线程结束。只有当子线程结束后,整个程序才结束。
守护线程
在计算机科学中,daemon 指的是后台运行的程序。这个后台运行的程序我们称为守护线程程序。在 Python 中,threading 模块对 daemon
线程有着具体的含义。当程序退出时的时候,daemon 线程会立刻退出。当程序没有被设置成 daemon 线程的时候,当程序在终止之前,会等待所有的子线程退出才会退出。
在 Example 1 的示例中,当主线程输出 Main: all done
时,表明线程已经结束。但是由于子线程还没有结束,所以需要等待子线程输出 Thread 1: done
表明子线程结束后,整个程序才退出 Process finished with exit code 0。
如果查看 treading 模块的源码,可以看到在 threading._shutdown() 会遍历所有正在运行的线程,并在每一个没有设置 daemon
标志的线程上调用 .join() 方法。因此,程序在退出时会等待,因为线程本身正在 sleep(time.sleep(5)
)中。一旦完成并打印了消息,.join()
将返回,程序才可以退出。所以,当希望主线程结束后,子线程也随之结束,只需要在创建线程时,添加 daemon 属性即可。
| Example 2 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | import threading
import time
def my_thread_function(name):
print(f'Thread {name}: running')
time.sleep(5)
print(f'Thread {name}: done')
if __name__ == '__main__':
print('Main: before creating thread')
x = threading.Thread(target=my_thread_function, args=('1',), daemon=True)
print('Main: before running thread')
x.start()
time.sleep(1)
print('Main: after running thread')
print('Main: all done')
|
上述代码在创建线程时,标记了 daemon 的值为 True。所以,当主线程退出后,子线程也随之退出。
Main: before creating thread
Main: before running thread
Thread 1: running
Main: after running thread
Main: all done
Process finished with exit code 0
join() 方法
当一个线程被标记为守护线程后,希望主线程可以等待这个子线程退出后才退出,那么可以使用 .join() 方法完成这个功能。
| Example 3 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 | import threading
import time
def my_thread_function(name):
print(f'Thread {name}: running')
time.sleep(5)
print(f'Thread {name}: done')
if __name__ == '__main__':
print('Main: before creating thread')
x = threading.Thread(target=my_thread_function, args=('1',), daemon=True)
print('Main: before running thread')
x.start()
time.sleep(1)
print('Main: after running thread')
x.join()
print('Main: all done')
|
要让一个线程等待另一个线程完成,可以调用.join(),该语句将一直等待,直到每个线程都完成。上述代码执行后,输出的结果如下:
Main: before creating thread
Main: before running thread
Thread 1: running
Main: after running thread
Thread 1: done
Main: all done
Process finished with exit code 0
使用多线程
在实际的开发中,一般会启动数个子线程来完成不同或者相同的任务。Example 4 模拟在后台启动 5 个线程:
| Example 4 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | import logging
import threading
import time
def my_thread_function(name):
logging.info(f'Thread {name}: running')
time.sleep(5)
logging.info(f'Thread {name}: Exit')
if __name__ == '__main__':
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
threads = list()
for i in range(5):
logging.info(f'Main: Creating Thread {i}')
x = threading.Thread(target=my_thread_function, args=(i,), daemon=True)
logging.info(f'Main: Creating Thread {i} successfully')
threads.append(x)
logging.info(f'Main: Starting Thread {i}')
x.start()
for i, thread in enumerate(threads):
logging.info(f'Main: Call join() of Thread {i}')
thread.join()
logging.info('Main: Exit')
|
在主线程中,第 13-14 行初始化了日志信息,目的是为了方便后续代码的输出能够更加的观察到主线程和子线程的状态。第 17 行创建了一个
list 列表用于保存线程,目的是可以在主线程中调用这些子线程的 .join 方法,让主线程可以等待子线程结束。第 20
行通过遍历的方式依次创建子线程,并将它们设置成守护线程,然后把这些线程保存到 list 列表中。第 24 行调用 start 方法启动子线程。第
26-28 行,依次获取到创建的子线程,然后调用 .join 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 | 12:57:54: Main: Creating Thread 0
12:57:54: Main: Creating Thread 0 successfully
12:57:54: Main: Starting Thread 0
12:57:54: Thread 0: running
12:57:54: Main: Creating Thread 1
12:57:54: Main: Creating Thread 1 successfully
12:57:54: Main: Starting Thread 1
12:57:54: Thread 1: running
12:57:54: Main: Creating Thread 2
12:57:54: Main: Creating Thread 2 successfully
12:57:54: Main: Starting Thread 2
12:57:54: Thread 2: running
12:57:54: Main: Creating Thread 3
12:57:54: Main: Creating Thread 3 successfully
12:57:54: Main: Starting Thread 3
12:57:54: Thread 3: running
12:57:54: Main: Creating Thread 4
12:57:54: Main: Creating Thread 4 successfully
12:57:54: Main: Starting Thread 4
12:57:54: Thread 4: running
12:57:54: Main: Call join() of Thread 0
12:57:59: Thread 0: Exit
12:57:59: Main: Call join() of Thread 1
12:57:59: Thread 2: Exit
12:57:59: Thread 1: Exit
12:57:59: Main: Call join() of Thread 2
12:57:59: Main: Call join() of Thread 3
12:57:59: Thread 3: Exit
12:57:59: Thread 4: Exit
12:57:59: Main: Call join() of Thread 4
12:57:59: Main: Exit
Process finished with exit code 0
|
仔细观察,可以发现子线程的退出似乎顺序错乱了。尤其是第 24-25 行,明明是 Thread 1 先创建,Thread 2 后创建,但是 Thread 2
却先退出,而 Thread 1 后退出。这是因为线程的运行顺序是由系统决定的,很难预测系统在调度过程中,哪个线程会被调度。
ThreadPoolExecutor
从 Python 3.2 开始,可以使用 ThreadPoolExecutor
多线程管理类降低线程创建的复杂性。创建它的最简单方法是使用上下文管理器的 with 语句,用它实现对线程池的创建和销毁。
| Example 5 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | import concurrent.futures
import logging
import time
def my_thread_function(name):
logging.info(f'Thread {name}: running')
time.sleep(5)
logging.info(f'Thread {name}: Exit')
if __name__ == '__main__':
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(my_thread_function, range(10))
|
第 16-17 行,使用 ThreadPoolExecutor 作为上下文管理器,设置最大线程数量为 5 个。使用 map 方法将my_thread_function
函数应用到 range(10)生成的 10 个任务上。这会创建 10 个线程,每个线程执行一次my_thread_function,并传递从 0 到 9
的数字作为参数(即name的值)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | 13:18:03: Thread 0: running
13:18:03: Thread 1: running
13:18:03: Thread 2: running
13:18:03: Thread 3: running
13:18:03: Thread 4: running
13:18:08: Thread 0: Exit
13:18:08: Thread 5: running
13:18:08: Thread 1: Exit
13:18:08: Thread 6: running
13:18:08: Thread 2: Exit
13:18:08: Thread 7: running
13:18:08: Thread 3: Exit
13:18:08: Thread 8: running
13:18:08: Thread 4: Exit
13:18:08: Thread 9: running
13:18:13: Thread 5: Exit
13:18:13: Thread 6: Exit
13:18:13: Thread 9: Exit
13:18:13: Thread 7: Exit
13:18:13: Thread 8: Exit
Process finished with exit code 0
|
同样的,在执行过程中线程的调度顺序是由系统决定的。
竞态条件
竞态条件(Race Condition)是指在并发编程中,当多个线程或进程对共享资源进行操作时,由于执行顺序不确定,导致程序行为不可预期的情况。特别是当操作的顺序依赖于线程的调度和执行速度时,竞态条件会引发错误或不一致的结果。
Example 6 模拟了一个竞态条件的例子。定义一个 FakeDatabase 模拟更新数据库,然后在主线程中开启 2 个线程操作数据库:
| Example 6 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | import concurrent.futures
import logging
import time
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
logging.info("Thread %s: starting update", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info("Thread %s: finishing update", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.update, index)
logging.info("Testing update. Ending value is %d.", database.value)
|
由于两个线程几乎同时访问和修改 FakeDatabase 的 value 属性,它们会读取相同的 value
值并对其进行更新。这样,线程间的竞争条件可能会导致 value 的最终值不如预期(预期的值是 2):
| 13:24:06: Testing update. Starting value is 0.
13:24:06: Thread 0: starting update
13:24:06: Thread 1: starting update
13:24:06: Thread 0: finishing update
13:24:06: Thread 1: finishing update
13:24:06: Testing update. Ending value is 1.
|
锁实现同步
为了解决竞态条件出现结果不符合预期的情况,通常需要使用同步机制,如锁(Locks)来确保对共享资源的操作是原子的和一致的。Python
中把锁使用 Lock 方法代替,在其他语言中类似的操作出称为 Mutex。Mutex 源于MUTual EXclusion,与 Python 中的 Lock
作用相同。Lock 宛如通行证,一次只能有一个线程拥有Lock,任何其他想要 Lock 的线程都必须等到 Lock 持有者释放。
在 Python 中,可以使用 with 语句简化锁的获取 .acquire() 和 释放 .release() 操作。当 with 语句执行时自动获取锁,当 with
中的代码块全部执行完成后,自动释放锁。
| Example 7 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | import concurrent.futures
import logging
import threading
import time
class FakeDatabase:
def __init__(self):
self.value = 0
self.lock = threading.Lock()
def locked_update(self, name):
logging.info("Thread %s: starting update", name)
with self.lock:
logging.info(f'Thread {name} has lock.')
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info(f'Thread {name} release lock.')
logging.info("Thread %s: finishing update", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.locked_update, index)
logging.info("Testing update. Ending value is %d.", database.value)
|
第 10 行定义了一个成员变量保存线程的锁。第 14-19 行,对操作数据的代码添加锁,避免多线程同时操作数据源。也就是说,当运行到第
14-19 行代码时,有且仅有一个进程可以获取到这个锁,另外一个线程没有获取到锁,只能够等待锁的释放后,才可以继续执行。
死锁
死锁(Deadlock)是指两个或多个线程在等待彼此释放资源,从而导致程序无法继续执行的情况。每个线程持有对方需要的资源,但这些资源都被锁住,从而形成一个循环等待的状态。
| Example 8 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38 | import threading
from time import sleep
lock1 = threading.Lock()
lock2 = threading.Lock()
def fun1(name):
with lock1:
print(f'Thread {name} acquired lock1')
sleep(1)
print(f'Thread {name} wait for lock2')
with lock2:
print(f'Thread {name} Acquired lock2')
print(f'Thread {name} released lock2')
print(f'Thread {name} released lock1')
def fun2(name):
with lock2:
print(f'Thread {name} acquired lock2')
sleep(1)
print(f'Thread {name} wait for lock1')
with lock1:
print(f'Thread {name} Acquired lock1')
print(f'Thread {name} released lock1')
print(f'Thread {name} released lock2')
if __name__ == "__main__":
t1 = threading.Thread(target=fun1, args=('T1',))
t2 = threading.Thread(target=fun2, args=('T2',))
t1.start()
t2.start()
t1.join()
t2.join()
|
Example 8 示例中,thread1 先获取 lock1,然后尝试获取 lock2。而 thread2 先获取 lock2,然后尝试获取 lock1
。如果两个线程几乎同时执行,可能会导致死锁,因为 thread1 等待 thread2 释放 lock2,而 thread2 等待 thread1
释放 lock1,两者形成循环等待。
Thread T1 acquired lock1
Thread T2 acquired lock2
Thread T1 wait for lock2
Thread T2 wait for lock1
// 程序无法停止,一直等待
为了避免死锁,可以从以下这些角度出发:
- 避免嵌套锁:尽量避免在一个锁的持有状态下请求其他锁。
- 锁顺序:确保所有线程以相同的顺序请求锁,以避免循环等待。
- 使用超时:使用锁的超时机制(如
acquire(timeout=...))来防止无限期地等待锁。
Example 8 可以修改锁的顺序,从而避免发生死锁:
| Example 8 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | import threading
from time import sleep
lock1 = threading.Lock()
lock2 = threading.Lock()
def fun1(name):
with lock1:
print(f'Thread {name} acquired lock1')
sleep(1)
print(f'Thread {name} wait for lock2')
with lock2:
print(f'Thread {name} Acquired lock2')
print(f'Thread {name} released lock2')
print(f'Thread {name} released lock1')
def fun2(name):
with lock1:
print(f'Thread {name} acquired lock1')
sleep(1)
print(f'Thread {name} wait for lock2')
with lock2:
print(f'Thread {name} Acquired lock2')
print(f'Thread {name} released lock2')
print(f'Thread {name} released lock1')
if __name__ == "__main__":
t1 = threading.Thread(target=fun1, args=('T1',))
t2 = threading.Thread(target=fun2, args=('T2',))
t1.start()
t2.start()
|
由于修改了获取锁的顺序,每个线程都在尝试以相同的顺序获取锁:lock1 然后 lock2
。虽然在某些情况下,可能会有线程在获取一个锁时被阻塞,但由于锁的顺序是一致的,它们不会形成循环等待的状态。
在这段代码中,如果两个线程几乎同时启动,它们可能会这样执行:
t1 获取 lock1。t2 尝试获取 lock1,但 t1 已持有此锁,因此 t2 会阻塞。t1 在 sleep 后尝试获取 lock2。- 一旦
t1 成功获取 lock2,它继续执行并释放 lock2 和 lock1。
t2 在 t1 释放 lock1 后获取 lock1,然后尝试获取 lock2。- 由于
t1 已经释放了 lock2,t2 成功获取 lock2。
因此,尽管每个线程都在请求相同的锁,但是因为它们按照相同的顺序获取锁,并且没有形成循环等待,因此代码中的锁操作不会导致死锁。